In 2019, Holman, Payne, and Pál published a remarkable research note in which they demonstrated that Sedna can be extracted at high signal-to-noise from the TESS Full Frame Images. The idea is that by shifting and stacking the pixels that track the orbit, one gradually builds up an image of a moving body that is far too faint to show up with significance on any individual frame (Sedna is magnitude 20.2).

This is not a particularly easy feat. You have to understand the TESS data structures and frame registration. You have to do a careful job with background noise, background stars, and fairly daunting systematics that stem from the spacecraft’s observing cycle. You need to correctly calculate how Sedna will move across the frame during the period of observation.
Every time there’s been a major new release of a frontier model, I’ve asked the new arrival to find Sedna in the TESS data. GPT-4 failed miserably. So did its various successors up to, but not including GPT 5.4 in a chat instance paired with OpenAI’s Codex operating from VScode. That agentic pairing did the job successfully, and with considerable élan. I’ll refrain from trying to drum up some momentous big-picture moment, and just show the result.
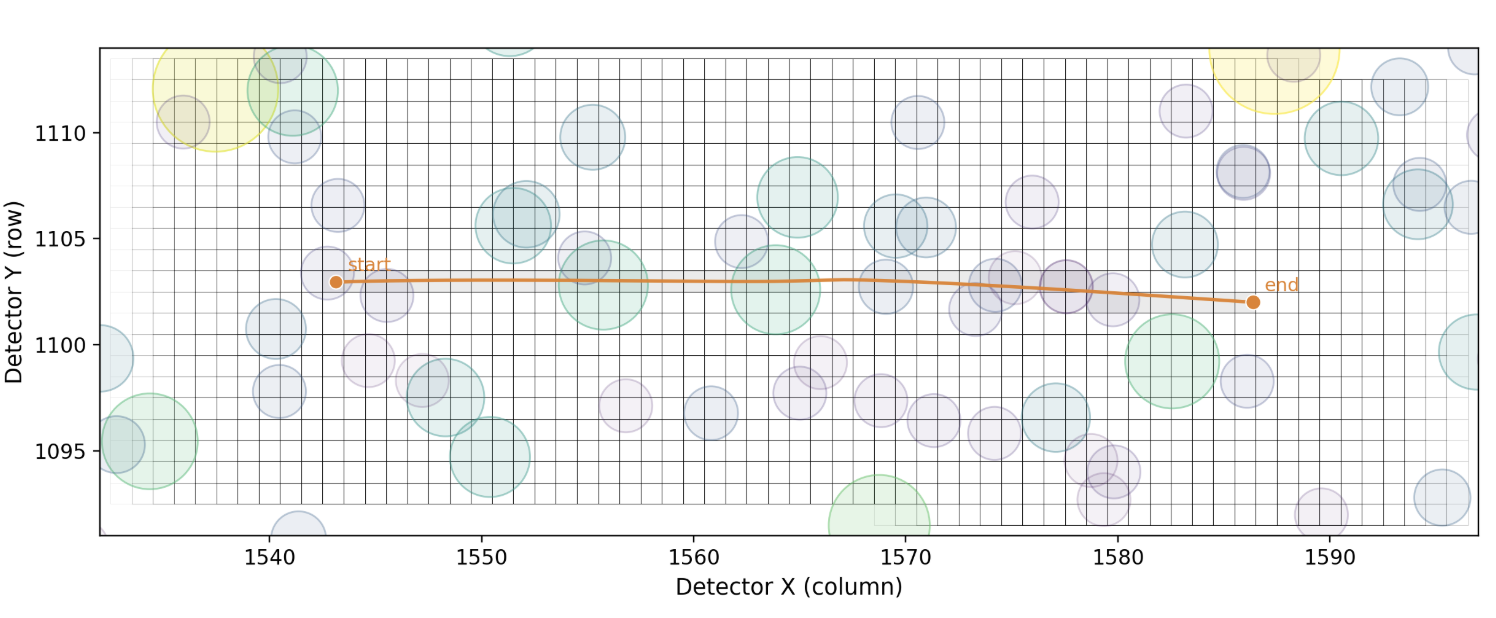
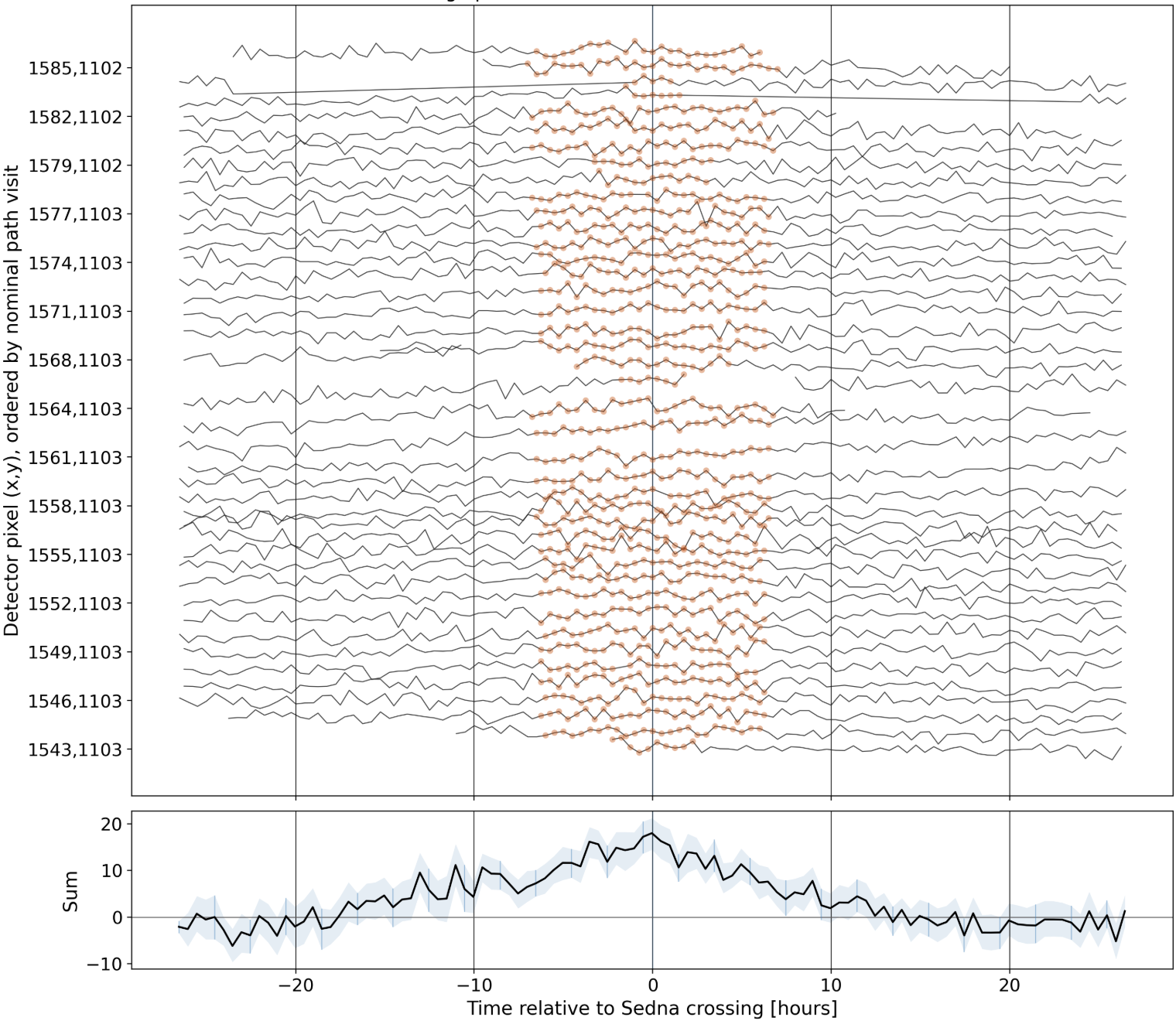
In the above image, the background stars (12th through 17th magnitude) in the field are shown with their approximate footprints on the pixels, with Sedna’s track during sector 5 running from left to right. The agent focused on just the pixels holding Sedna’s centroid, and produced a clever visualization of the dwarf planet’s trace through the data:
From there, it was straightforward to de-trend, filter, stack, and bang, there it is: