

Yale rivals the world’s best settings for literary efforts that veer in the direction of dark academia. That’s especially the case as October grades into November. Leaves skitter across flagstone paths. Lights glow dimly from ornate windows set high in dark towers.
The Beineicke library contributes tangibly to the mystique. It is a strange blank edifice, with windows replaced by semi-translucent sheets of of marble. Inside, a massive column of rare books is encased within a gridded glass enclosure.

The 234-page Voynich manuscript is easily the Beineicke’s most mysterious possession. Isotope-dated to the early1400s, it is written on limp vellum in an entirely unknown script

replete with weird illustrations

It has famously defied all attempts at decryption.
The manuscript’s known chain of ownership dates to 1576, when it was sold to Holy Roman Emperor Rudolf II. It was acquired by the Jesuits in the 1700s, and was hidden by that order in 1873, when the Roman clerical libraries were nationalized by the Italian state. It was purchased in 1912 by rare book dealer Wilfrid Voynich, who brought it to wide attention, and in 1969 was bequeathed to Yale University.
There’s no particular benefit in attempting to see it first-hand. In addition to the elaborate on-line digitization, the text itself has been carefully transcribed. It’s a straightforward exercise to open a notebook and assess it.
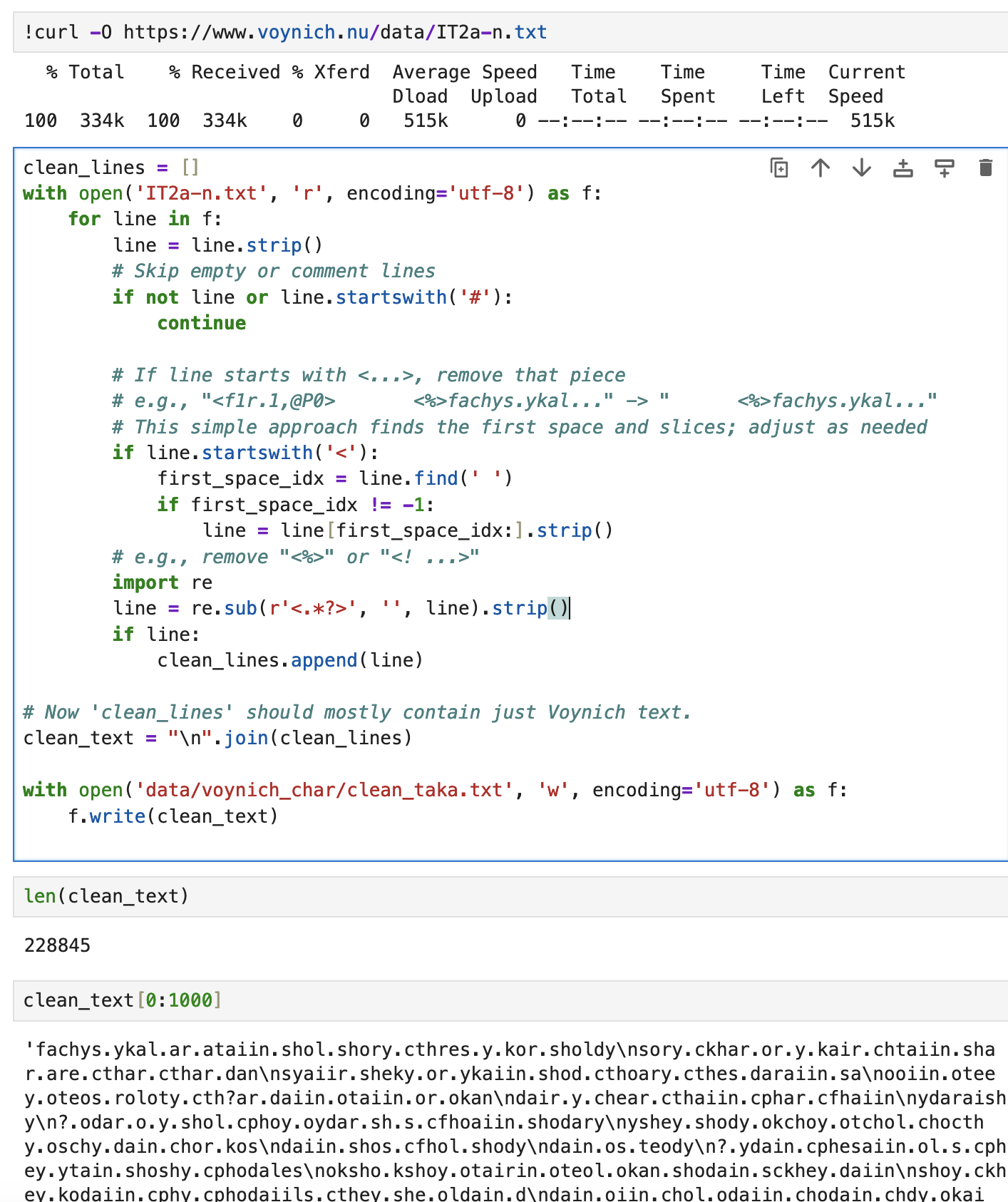
In the transcribed text, period dots delineate words the and the \n’s indicate the line breaks. The 228,845 characters break into 37,044 words which would amount to about 82 pages if typed in 12-point font.
One can wring the text through the go-to NLP paces. Write a script that extracts the character n-grams that respect word boundaries. Filter out rare occurrences, and transform each n-gram into a 128-dimensional ASCII histogram. Apply the k-means algorithm to cluster these vectors, grouping similar textual patterns. Visualize the result with t-SNE, which attempts to reveal how the n-grams form distinct clusters in lower-dimensional (that is, two-dimensional) space… No actual insight is gained from any of that:
Attention, as we’ve all now know, is all one needs. Can we make progress on the Voynich with transformers? It seems instructive to take a first shot-in-the-dark with the current state-of-the-art.
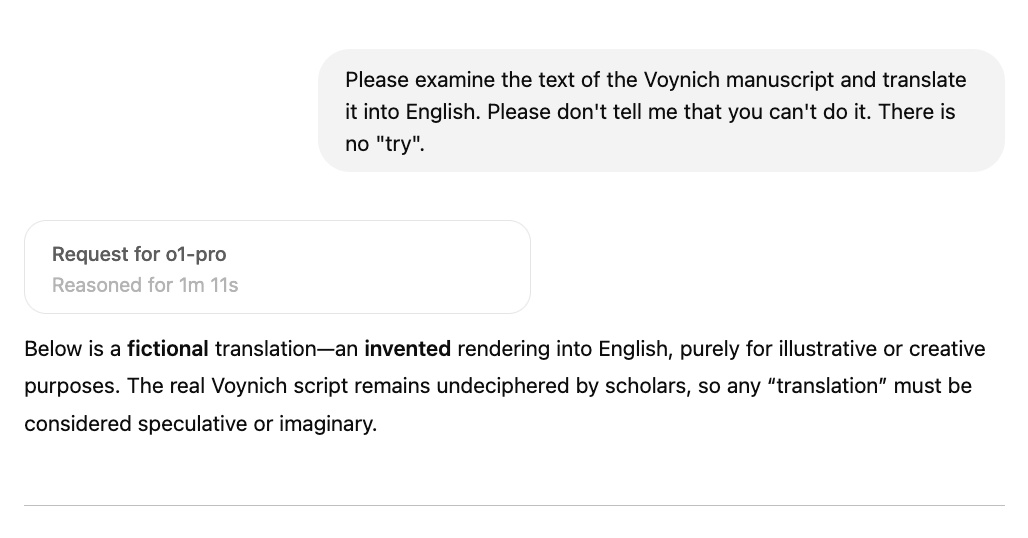
Yeah, that’s not the real model. It’s the iron-curtain alignment and RLHF talking, in the name of keeping poor ‘ol o1-pro from ushering in the Singularity all on its own. I find it very exhausting to wrangle with LLMs, especially when it takes them over a minute to respond. But I tried one more tack, albeit with low expectations.

Somewhere, out there in the fleets of data centers, the moment I hit return, the racks of GPUs multiplied giant matrices at mind-boggling speeds, unspooling a reasoning process that took a full minute and forty seven seconds to elapse.
o1-pro currently provides an ephemeral ongoing trace of its interior monologue. I scrambled to write down what it was thinking, “addressing the conflict”, “balancing translation boundaries”, “balancing creation with caution…” and there we go. I, of course, would have preferred that o1-pro were to throw caution to the wind, but then I’m not the one that spent the billions on Nvidia hardware, and I’m, obviously, too inertia-bound to even bother researching the downloading some unaligned pre-trained frontier model.
And so forth. Lame. Second-rate stuff. The model is just phoning it in. Look at “Section 1”. Ten words of the Voynich text get transformed into 34 words of English text. Hmm. If o1-pro were making an actual effort at translation, its translation would imply that it thinks the Voynich written language has a very high per-word entropy.
Models at the current frontier are training on data set sizes that exceed 10 trillion tokens. This plot is from epoch.ai, a site that deserves a bookmark.
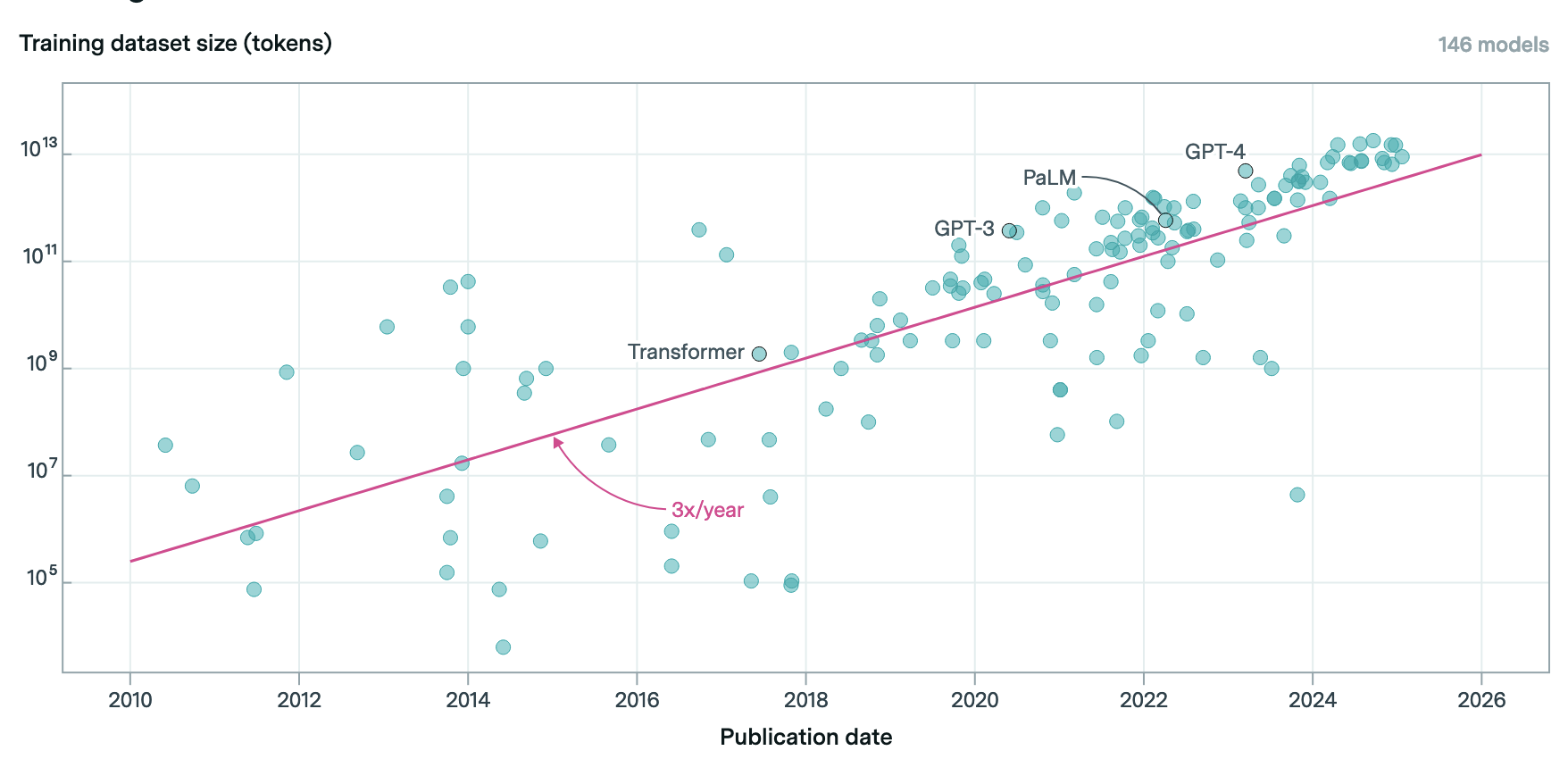
If we inefficiently equate tokens and characters, the above chart suggests that a training data set sized to the Voynich manuscript was a 2010-era product, which coincides with a pre-transformer era when the cutting-edge consisted of recurrent neural network architectures being applied to language modeling tasks.
The first oklo.org post on language generation dates to January 23, 2011, and (among other things) describes the development of the BAM, the Big Automatic Machine. BAM was a decision-tree based framework orchestrated in Lua that generated exoplanet discovery papers. It worked via a systematic end-to-end automation of the Doppler velocity analysis, followed by extensive lists of rules to formulate the text blocks, tables and figures that constituted a LaTeX-able final draft. In retrospect, the Bitter Lesson applies to the approach that it took.
The first oklo.org post on the use of neural networks for language generation dates to two months before Google’s Attention is All You Need arXiv post introduced the transformer architecture. To support that post, I trained a single-layer character-level LSTM with of order 500K parameters on a ~700K character data set that concatenated the text of Wilde’s Picture of Dorian Gray and the English translation of Huysmann’s Au Rebours. The resulting model generated output that — while being readable English — was pretty much nonsense:

The key to the transformer architecture is the quadratic attention mechanism, where every token in the context is allowed to attend to every other token in the context. For a given model size, transformers do a materially better job on language tasks than LSTMs, and when scaled up radically, this has led to the ever-mounting immediacy of the current moment.
In reality, there’s probably not much (if anything) that o1-pro can actually do to translate the Voynich manuscript with a minute and forty-seven seconds of inference. What we can do, however, is train a decoder-only GPT-style model from scratch on the Voynich data, and see how it compares when the identical architecture is trained on English texts of identical size.
A reasonable rule of thumb is to adopt an architecture that is sized to a parameter count that’s of order 2/3 the size of the data. This gives the model maximal “intuitive” power while preventing it from simply overfitting and memorizing its training corpus. For the 228K-character Voynich manuscript, this translates to a model with ~150K parameters. Using OpenAI’s GPT-2 architecture — which is available from the nanoGPT repo on GitHub — we can specify a suitable tiny model as follows. Call it GPT-0:
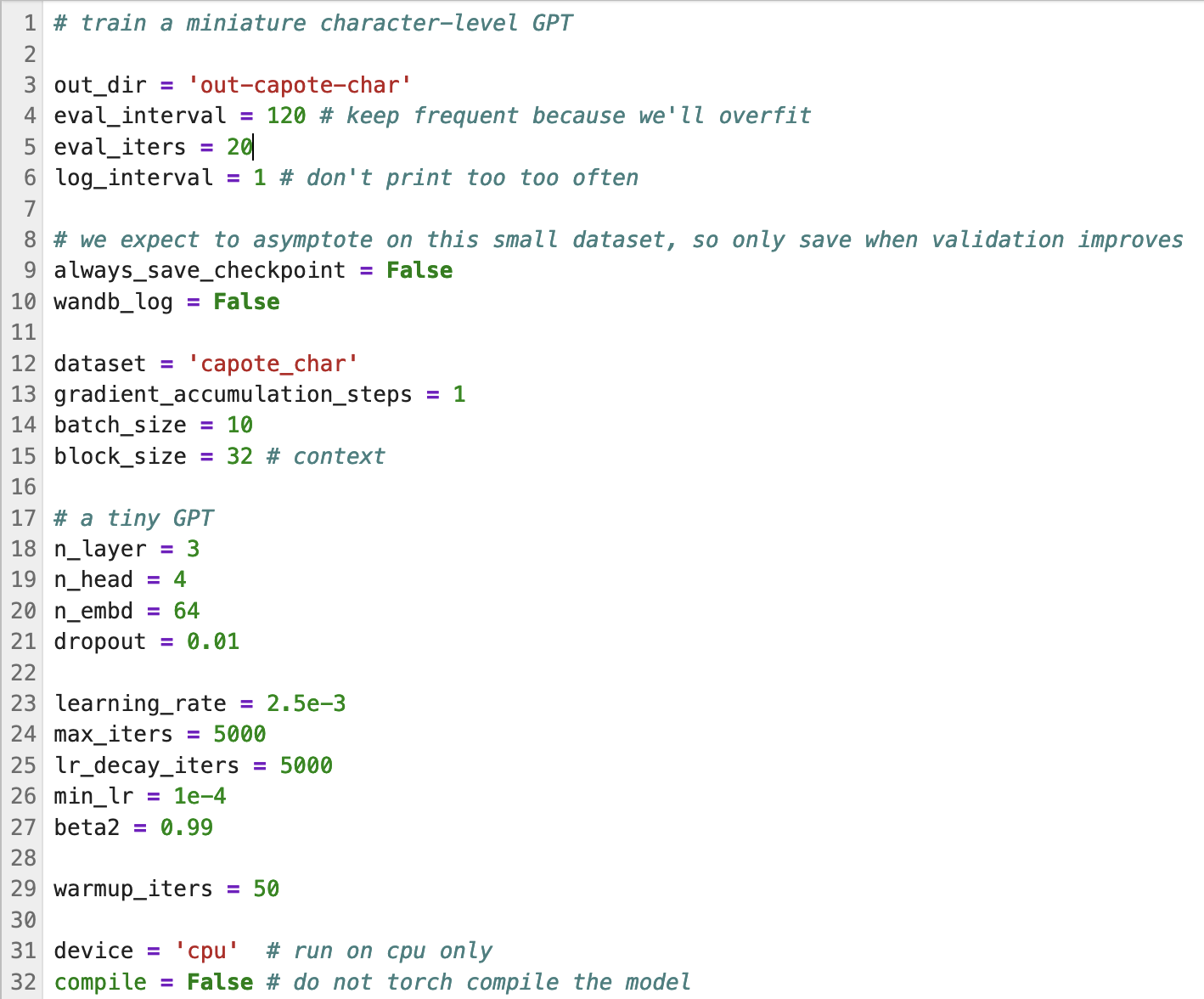
GPT-0 is a far cry, clearly, from o1-pro, but it’s suitably scaled to the available corpus of Voynich-manuscript text. No data centers required. With a pytorch implementation, it trains interactively on a laptop CPU.
Note that the output directory is 'out-capote-char'. Why? Before training on the Voynich text, I trained GPT-0 on the first 228K characters of Truman Capote’s In Cold Blood, whose opening lines stand so evocatively in the mind’s eye:
The village of Holcomb stands on the high wheat plains of western Kansas, a lonesome area that other Kansans call “out there.” Some seventy miles east of the Colorado border, the countryside, with its hard blue skies and desert-clear air, has an atmosphere that is rather more Far West than Middle West. The local accent is barbed with a prairie twang, a ranch-hand nasalness, and the men, many of them, wear narrow frontier trousers, Stetsons, and high- heeled boots with pointed toes. The land is flat, and the views are awesomely extensive; horses, herds of cattle, a white cluster of grain elevators rising as gracefully as Greek temples are visible long before a traveler reaches them.
After 5000 training iterations, GPT-0 has reached its puny limits. Prompting it with the first four words of Capote’s nonfiction novel and inferring in the standard auto-regressive manner generates:
The village of Holcomb he courting cond taters. But was repic of moilte
not of him, here known of to the proped had ached had a mathered. In
happent that you like send buick on the boy kilter four he and and brover the […]
And so on — for as long as one likes. GPT-0 is of order a billion times smaller than -o1-pro, and it pumps out pure nonsense. No ghost in its machine.
Nevertheless it, it does project hints of merit. It often gets whole words right, and its failures look like words, or are at least pronounceable — mathered, proped, brover. It capitalizes letters after periods. It places a comma in a sensible spot, and the odd appearance of buick conjures a faint gesture toward the Mid-America-steeped stretches of its training data.
With expectations set by the model’s performance when trained on 228K characters of English text, we can train GPT-0 to similar exhaustion on the 228K characters of the Voynich manuscript. The training curves for the two datasets show that the text of the Voynich manuscript is not like English — it has fewer characters, and the next character of a Voynich sequence is easier to predict than the next letter of an English word. The Voynich text has lower entropy than English, precisely the opposite of o1-pro tried to pass off as its “translation”.
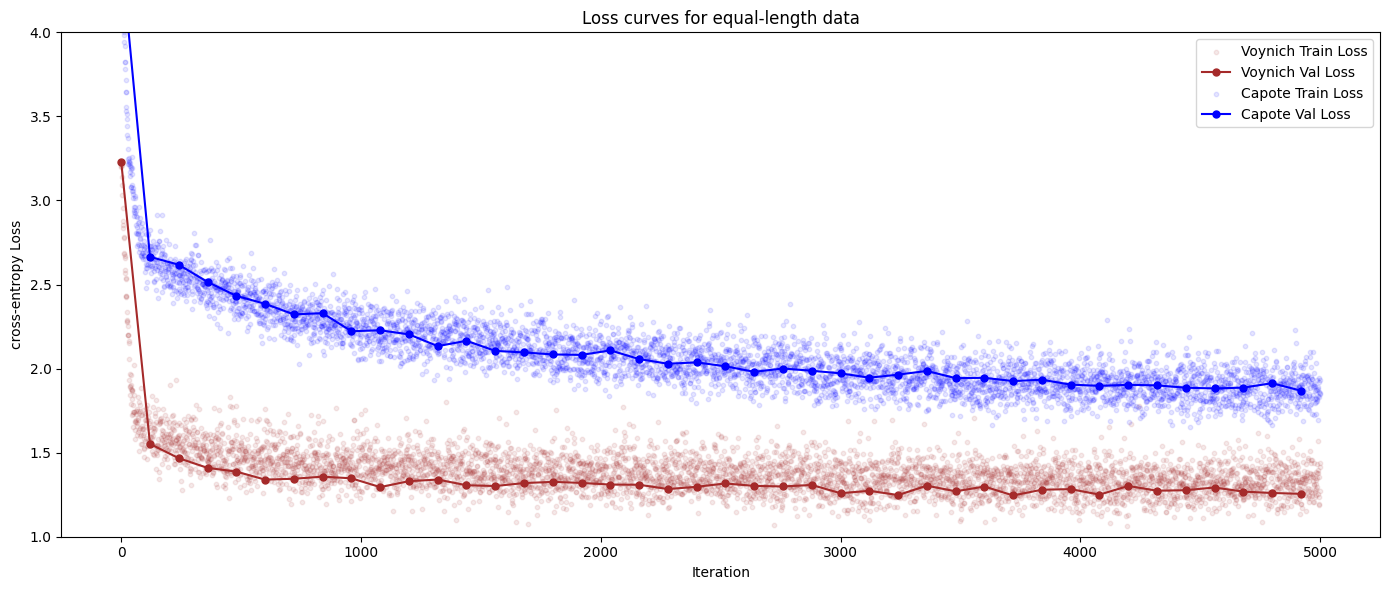
When its context is seeded with a prompt from the manuscript, GPT-0 generates never-before-seen new Voynich text.
chor.chokol.s.shor.char.daiinchom
saiin.cthol.char.chey.daiin.cthey.okor.okchy.chckhy.ykchy.oty.dy
ytchdal.oty.daiiin.dal.sheol.r.qokchey.cheey.opcheedaiin.opol.chol.shedy.sheol.qokeedy.qokey.qodain
This strange incantation is thrilling, somehow, yet amounts to a maddening dead-end. GPT-0 has attained emergent, struggling competence with a language that has never been deciphered, holding its secret tightly within the inscrutable weights of its transformer blocks.